Getting Started with Python Pandas.
In this article, you will learn What is Pandas and What makes it the most popular Python library for Data Analysis.

Pandas package is the most powerful tool when it comes to data analysis in Python. Pandas is one of the libraries that makes python a great programming language for data analysis.
[pandas] is derived from the term "panel data", an econometrics term for data sets that include observations over multiple time periods for the same individuals. -- Wikipedia.
You should learn pandas if you considering data science as a career. In this article, you will learn about Pandas, Its features, and pandas data structures.
What is Pandas?
Pandas is an open-source Python library used for high-performance data manipulation and data analysis using its powerful data structures.
Pandas makes manipulating, analyzing, and visualizing data much easier. It builds on packages such as NumPy and Matplotlib. So before you start learning Pandas, you should learn the basics of Numpy and Matplotlib.
Pandas help you to extract a piece of meaningful information from data by cleaning and transforming it.
Using Pandas you will be able to find the answers to some statistical questions such as what is mean, median, standard deviation, min, max of data. How data is distributed, how data are related to each other etc.
Features
These are some of the important features of Python pandas that we will use while Data Preprocessing and Data Analysis work.
- Pandas supports fast and efficient DataFrame objects with default and customized indexing.
- Easy Handling of Missing data.
- Reshaping and pivoting data sets.
- Label slicing, Indexing, and Subsetting of large data sets.
- Columns can be inserted and deleted from DataFrame.
- Provides high-performance merging and joining of data.
- Pandas makes it easy to convert different types of files into a data frame object.
- Pandas provides powerful and flexible groupby functionality for both aggregating and transforming data.
- Provides time-series functionality such as date range generation and frequency conversion, moving window statistics, date shifting, and lagging.
Pandas Data Structures
Pandas support two data structures
- Series
- DataFrame
To get started with Pandas data structure first let's import and load NumPy and Pandas libraries.
import numpy as np
import pandas as pd
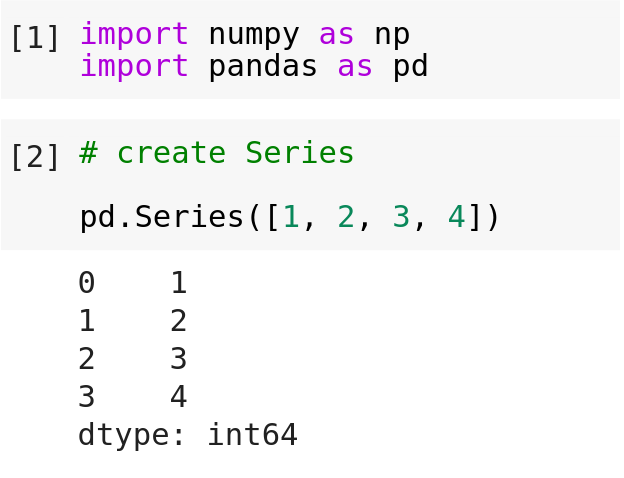
1. Series
Series is a One-dimensional labeled array with homogeneous data with labeled axes. The labeled axes are referred to as the Index.
Creating Series in Pandas.
pandas.Series(data, index = index)
Here data can be a
- List
- Dictonary
- ndarray
- or a Scalar value
The index can be a list of axis labels. The length of the index must be matched with the data. It's not mandatory to pass the index, if not passed then the default index with values from 0 to len(data)-1 will be assigned.
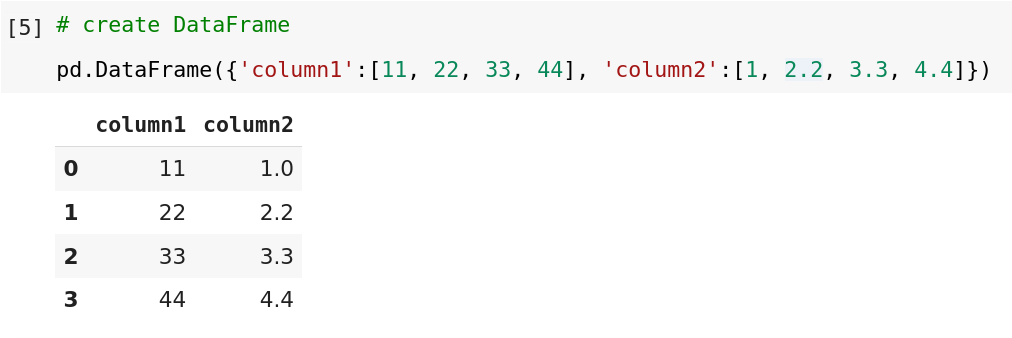
2. DataFrame
DataFrame is a two-dimensional array with heterogeneous data structures with labeled axes. In DataFrame, data is stored in tabular data format with rows and columns like SQL tables or excel spreadsheets, or a dictionary of the series objects.
Creating DataFrame in Pandas.
pandas.DataFrame(data, index = index, columns = columns)
Like Series, DataFrame can accept different types of input as Data.
- Dictionary of ndarrays, lists, dictionaries, or Series.
- 2D ndarrays
- A Series
- Another DataFrame
Along with the data, you can pass index(row labels) and columns(column labels/names) as arguments.
This is just an introduction to Pandas DataStructure, we will learn data structures in more detail in coming tutorials.
Thank you for reading, I hope this helps you. See you in next tutorial. :)




