How to Handle Missing Data in Pandas?
In this article, we will discuss methods to handle missing data in Pandas.

The real-world data is rarely clean and can have missing data for a number of reasons. For example in surveys, if data is not provided may be because a particular question is not appropriate to a particular person then no data is recorded or left blank. These values are considered as missing values(null/None/ NaN) in our DataFrame.
Data is collected from different sources so, there is the possibility that there are different types of missing data. Handling and cleaning missing data is important as most of the machine learning algorithms do not support data with missing values. Data preprocessing and data cleaning is the first step in any data analysis and that is why, In this article, we will discuss how to handle missing data in Pandas.
What are Missing Values?
Missing data occur when no data value is stored for a feature/ variable in an observation. These values could be found in datasets as ?, null, na, 0, or just blank space or NaN.
Here, I am using this simple dataset with some null values. So, let's import the dataset.
import pandas as pd
data = pd.read_csv("data.csv")
data
output
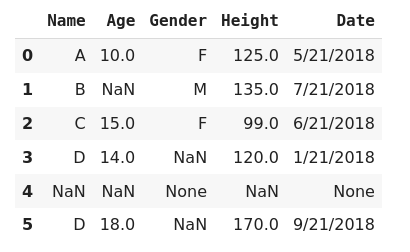
Let's take a look at this dataset, we have some NaN and None values in the Age and Gender columns, and also we have an entire 5th row with null values.
Missing data occur in many formats, it could be a particular value as 0, -1 for numeric columns, or even Noneor na. We can customize these different missing data formats into a single NaNs by using the na_values argument of the read_csv method of DataFrame.
# Customizing missing data values.
>>> data = pd.read_csv('data.csv', na_values=['None'])
>>> data
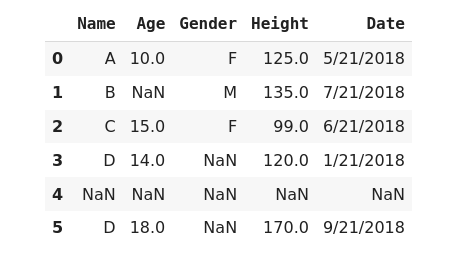
Now, we have all missing data in a single format as NaN. NaN (Not A Number) is a standard format for missing data in Pandas.
You can use this when you need to map a particular list of values that must be treated as missing values in the entire dataset. But if you want to specify a particular value that must be considered as missing data for particular columns, then you have to pass a dictionary of columns as key with that value.
for example
pd.read_csv('data.csv', na_values = {'col_1': [0], 'col_3': ['None'], 'col_5':[-1]})
How to handle missing data?
Now that we've identified and annotated missing data properly we can clean our data, There are different approaches to handle this missing data.
- Removing missing values from data.
- Filling missing data values.
1. Removing null values from data.
Removing rows or columns with null values could be one of the approaches to handle missing values in the dataset. This can be done by using dropna() method.
# To remove rows with missing values.
>>> data.dropna(axis=0)
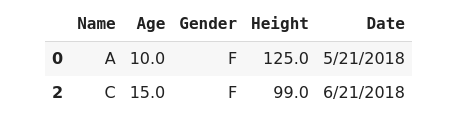
The axis parameter specifies whether you want to drop rows or columns with missing data, set axis=0 to remove rows with missing values, or set axis = 1 to remove columns with missing data. By default axis values are set to 0.
This returns a new data frame by dropping null values without changing the original DataFrame, you'd have to re-assign the DataFrame to itself to make changes to the original DataFrame. The inplace=Truecan be use to make changes to the original DataFrame as it makes changes to the existing dataframe and returns None.
>>> data.dropna(axis=0, inplace=True)
This is an easy approach to handle missing data, using dropna we remove all null values but we also lose other valuable data that could be helpful in analysis. We can control whether we want to drop rows with one null value or all null values using the how parameter.
how{‘any’, ‘all’} default ‘any`
any: If any NA values are present, drop that row or column.all: If all values are NA, drop that row or column.
We can see that our data has one row with all null values, so let's drop that row using how parameter.
# drop only rows with all null values.
>>> data.dropna(axis=0, how='all')
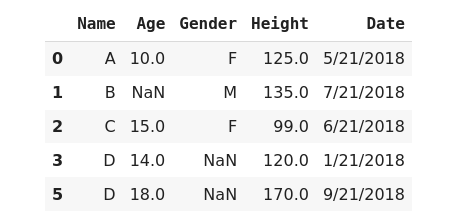
Did you notice? we still have NaN values, It removes the only row that contains all values as null values. We can use the same approach to remove null values from columns using axis=1
Removing rows or columns with missing data approach is good to use only when we have all rows or column values are null like in the above example.
2. Filling missing data values.
The most common approach to handle missing data is to fill in missing data with some appropriate value. For this we can use DataFrame.fillna() method.
- Using mean, median, and mode value.
- Using a constant value
- Using Forward Fill or Backward Fill method of
fillna()method.
1. Fill NA values with column mean, median, or mode value.
- Mean
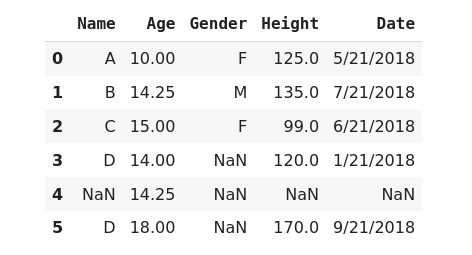
When a column is a numeric type and normally distributed then we can fill the missing value of the column with its mean value.
>>> data['Age'].fillna(data.Age.mean(), inplace=True)
>>> data
- Median
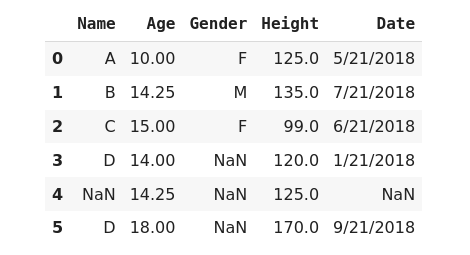
When a column is a numeric type but data is right or left skewed then we can fill the missing value of the column with its median value.
>>> data['Height'].fillna(data.Height.median(), inplace=True)
>>> data
- Mode
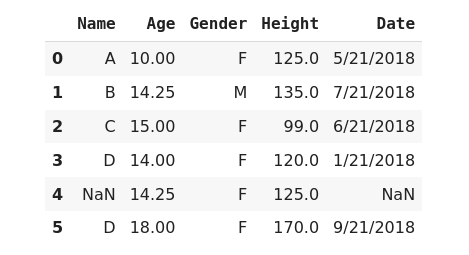
When we have missing data in the categorical column then we can fill the missing value of that column with its mode value.
>>> data['Gender'].fillna(data.Gender.mode()[0], inplace=True)
>>> data
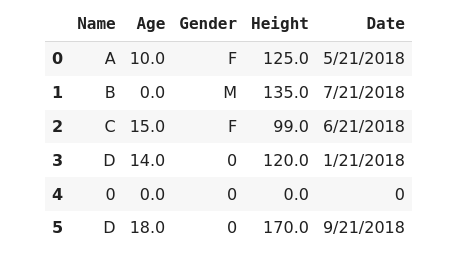
2 Fill NA values with a constant scalar value.
## filling all missing data with scalar value.
>>> data.fillna(0)
3. Fill Na values with forward fill or backward fill methods.
Forward filling method(ffill) This is method fills the missing values with the first non-missing value that occurs before it.
>>> data['Age'].fillna(method='ffill', inplace=True)
>>> data
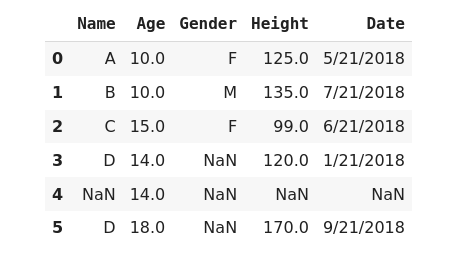
Backward filling method(bfill) This method fills the missing values with the first non-missing value that occurs after it.
>>> data['Height'].fillna(method='bfill', inplace=True)
>>> data
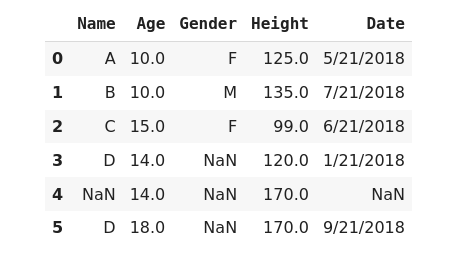
Filling null values with appropriate values may not be the perfect method. But this allows you to introduce values that don't impact the overall dataset.
These are the two approaches we can use to handle the missing data in Pandas. Cleaning data is the most important step in data analysis as it helps to understand and analyze data more effectively which leads to more accurate decisions.
Thank you for reading this article. I hope this helps you. See you in my next pandas tutorial. Take care. :)




